

















Introduction
Une base de données est un objet particulièrement difficile à définir puisqu’il est abordé en pratique selon différents points de vues :
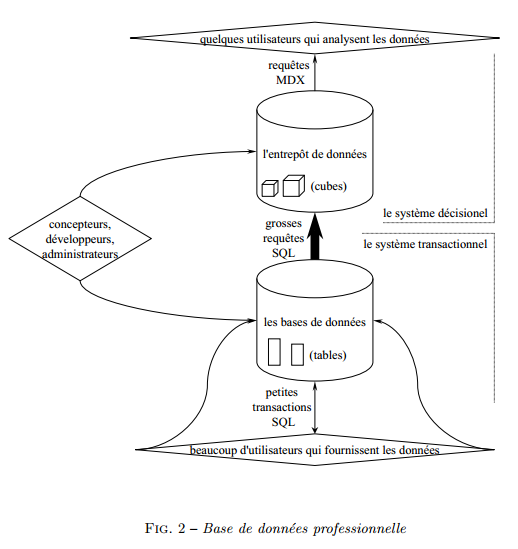
Dans une base de donn´ees personnelle (que l’on manipule dans le logiciel Access de Microsoft par exemple), on retrouve essentiellement un sch´ema ou je suis l’unique concepteur, développeur, fournisseur et analyste des données .- pour un utilisateur, une base de donn´ees est un espace ou il peut enregistrer des informations, les retrouver et les faire traiter automatiquement par un ordinateur (on retrouve l`a, l’étymologie du mot informatique) ;
- pour un développeur, une base de données est un ensemble de tables, de relations et de procédures écrites en SQL (Structured Query Language) ;
- pour un administrateur informatique, une base de données est un ensemble de données à sauvegarder et sécuriser.


Physiquement, le réseau informatique concerné par le traitement des données est organisé autour d’un ordinateur (ou un cluster d’ordinateurs) équipé de SQL Server et accompagné d’une baie de disques qui stockent les données (cf. figure 4).
A ce serveur sont connectés autant de stations de travail clientes que d’utilisateurs, que ce soit les opérateurs en amont, les managers en aval ou le service informatique. De plus en plus, ces utilisateurs passent par Internet, ce qui implique un nombre grandissant d’informations qui circulent entre le serveur web de l’entreprise et le serveur base de données

D’autres remarques sont à noter concernant le logiciel présenté ici :
- comme SQL Server a toujours quelque chose à faire, il tourne en permanence sur le serveur ; c’est ce que l’on appelle un service : on ne le d´emarre pas comme un simple exécutable et il continue de tourner quand on se d´econnecte ;
- on ne trouvera dans le logiciel SQL Server ni de formulaires ni d’états ; l’interfaçage graphique est laissé aux ordinateurs clients, comme par exemple les applications Visual Basic (dont Access), les applications textes ou encore les pages web. Par ailleurs, l’édition d’´etats est laisséeà d’autres logiciels, comme par exemple Crystal Seagate.
Le système transactionnel
En anglais on parle de syst`eme OLTP (On Line Transaction Processing). Il s’agit pour nous de concevoir et développer la base de données relationnelle et les transactions qui permettent de modifier les données. On propose de d´ecouvrir ici le langage Transact SQL qui est une version propre à SQL Server du langage SQL.Le langage SQL a été initialement conçu dans les années 1970 par la firme IBM. Il a été ensuite normalisé (la norme actuelle, SQL-2, date de 1992) et est devenu le standard de tous les SGBDR. Ce langage permet de masquer aux programmeurs les algorithmes de recherche des données dans des fichiers physiques eux-même structurés de manière très complexe et différemment selon les SGBDR. Transact SQL prend certaines libertés par rapport à la norme, mais la majeure partie de ce qu’on aborde ici est réutilisable avec un autre système de gestion.
Il se décompose en quatre sous-langages qui s’occupent de :
- la définition des données : création des tables, des contraintes, etc. ;
- la manipulation des données : sélectionner, insérer, supprimer et modifier ;
- le contrôle des donnêes : intégrité, droits d’accès, verrous et cryptage ;
- la programmation : procédures stockées, fonctions, déclencheurs.
Le lecteur est également invité à se rappeler les méthode de conception d’un bon schéma relationnel et à se souvenir qu’il est essentiel de connaître le métier des
utilisateurs d’une base de donn´ees avant de travailler dans celle-ci.
Syntaxe du langage SQL
Comme tout nouveau langage commen¸cons par apprendre la syntaxe de base.Tout d’abord on peut mettre autant d’espaces et de sauts de ligne que l’on veut entre les mots du langage. Cependant, on respectera les règles suivantes :
- une seule instruction par ligne ;
- la même indentation que dans le présent document ;
- et des lignes pas trop longues (visibles entièrement à l’écran).
Commentaires
On peut insérer des commentaires de deux fa¸cons :
- sur une ligne, à partir de deux tirets -- ;
- dans un bloc délimité par /* et par */.
/* cette requete selectionne
toutes les donnees de la
table Exemple */
SELECT * FROM Exemple
-- le * designe toutes les colonnes
Remarque : ne pas employer les caractères accentués (y compris dans les commentaires)toutes les donnees de la
table Exemple */
SELECT * FROM Exemple
-- le * designe toutes les colonnes
Noms
Tous les noms d’objets (table, colonne, variable, etc.) doivent respecter les règles suivantes :- ne pas dépasser 128 caractères parmi : les lettres (non accentuées), les chiffres, @, $, #, - ;
- commencer par une lettre ;
- ne pas contenir d’espace .
Par ailleurs, on est pas oblig´e de respecter la casse (i.e. il n’y a aucune diff´erence entre les majuscules et les minuscules). Mais on prendra l’habitude de laisser en majuscule les mots-cl´es du langage et seulement les mots-cl´es du langage.
Opérateurs
- Les opérateurs arithmétiques disponibles sont : +, -, *, / et % le reste par division entière ;
- les opérateurs de comparaison logique sont : <, <=, =, >=, > et <> (différent) ;
- les autres opérateurs logique sont : AND, OR et NOT ;
- et pour la concaténation des chaînes de caractères on utilise +.
doute.
Variables
Les principaux types disponibles sont :
| Type | Signification |
| INT | entier |
| DECIMAL(9,2) | montant à 9 chiffres (d´ecimaux) dont 2 après la virgule |
| REAL | réel flottant codé sur 24 bits |
| CHAR(64) | chaˆıne de caract`ere de longueur fixe 64 |
| VARCHAR(64) | chaîne de caract`ere de longueur variable mais inf´erieure ou égale à 64 |
| DATETIME | date et/ou heure avec une pr´ecision de 3.33 ms |
- dans un soucis d’économie d’espace, on peut utiliser pour les entiers les types SMALLINT, TINYINT et même BIT ;
- les entiers de type INT peuvent aller jusqu’`a un peu plus de 2 milliards, au del`a il faut utiliser le type BIGINT qui autorise des entiers jusqu’`a plus de 9000 milliards ;
- le nombre maximal de d´ecimales est 28 ;
- on peut choisir de stocker les réels flottants sur n bits avec le type FLOAT(n) (n inf´erieur ou ´egale à 53) ;
- les chaînes de caract`eres ne peuvent pas d´epasser 8000 caract`eres, au delà, il faut utiliser le type TEXT qui autorise plus de 2 milliards de caract`eres ;
- on peut définir son propre type, exemple3 4 :
sp_addtype CodePostal, CHAR(5)
- pour les conversions entre diff´erents type, il faut parfois employer l’instruction CAST.
affectation et affichage :
DECLARE @tva DECIMAL(3,3)
SET @tva = 0.186
PRINT @tva
SET @tva = 0.186
PRINT @tva
Structures
SQL offre les structures usuelles de tout langage.►Blocs
On peut d´elimiter un bloc de plusieurs instructions par BEGIN et par END. C’est la structure la plus importante du langage, elle est utilis´ee par toutes les autres structures, les transactions, les d´eclencheurs, les proc´edures stock´ees et les fonctions
►Branchements conditionnels
On peut parfois avoir besoin d’effectuer un branchement conditionnel, pour cela on dispose de la
structure conditionnelle suivante :
IF expression booléenne
... une instruction ou un bloc
ELSE faculatif
... une instruction ou un bloc
Exemple tiré de la base de données Northwind : on veut supprimer le client Frank
IF EXISTS(SELECT OrderID FROM Orders WHERE CustomerID = ’Frank’)
-- bref, s’il existe des commandes pour le client Frank
PRINT ’Impossible de supprimer le client Frank, car il fait l’’objet de commandes’
ELSE
BEGIN
DELETE Customers WHERE CustomerID = ’Frank’
PRINT ’Client Frank supprime’
END
-- bref, s’il existe des commandes pour le client Frank
PRINT ’Impossible de supprimer le client Frank, car il fait l’’objet de commandes’
ELSE
BEGIN
DELETE Customers WHERE CustomerID = ’Frank’
PRINT ’Client Frank supprime’
END
Remarque : les chaînes de caract`eres sont délimitées par une quote ’ et si la chaîne contient elle-même
une apostrophe ’, il suffit de doubler la quote ’’.
Une erreur très fr´equente consister à utiliser plusieurs instructions sans les délimiter par un bloc :
IF(@b <> 0)
PRINT ’On peut diviser car b est non nul’
@a = @a / @b
ELSE
PRINT ’On ne peut pas diviser car b est nul’
PRINT ’On peut diviser car b est non nul’
@a = @a / @b
ELSE
PRINT ’On ne peut pas diviser car b est nul’
On dispose également de la structure plus générale suivante :
CASE
WHEN expression booléenne THEN
... une instruction ou un bloc
WHEN expression booléenne THEN
... une instruction ou un bloc
... d’autres WHEN ... THEN
ELSE
... une instruction ou un bloc
END
Dans laquelle, les diff´erents cas sont évalués successivement.
Exemple tiré de la base de données Northwind : on veut savoir quel produit il faut réapprovisionner
SELECT ProduitID, ’Etat du stock’ =
CASE
WHEN(Discontinued = 1) THEN
’Ne se fait plus’
WHEN((UnitsInStock - UnitsOnOrder) < ReOrderLevel) THEN
’Seuil de reapprivionnement atteint : passer commande’
WHEN(UnitsInStock < UnitsOnOrder) THEN
’Stock potentiellement negatif : passer commande’
ELSE
’En stock’
END
FROM products
CASE
WHEN(Discontinued = 1) THEN
’Ne se fait plus’
WHEN((UnitsInStock - UnitsOnOrder) < ReOrderLevel) THEN
’Seuil de reapprivionnement atteint : passer commande’
WHEN(UnitsInStock < UnitsOnOrder) THEN
’Stock potentiellement negatif : passer commande’
ELSE
’En stock’
END
FROM products
Exercice : une erreur s’est gliss´ee dans l’exemple pr´ec´edent.
►Boucles conditionnelles
La seule fa¸con d’effectuer une boucle est d’utiliser la structure suivante :WHILE expression bool´eenne
... une instruction ou un bloc
On ne dispose pas de boucle FOR pour la simple raison que les boucles WHILE suffisent :
DECLARE @i
SET @i = 0
WHILE(@i < @n)
BEGIN
...
@i = @i + 1
END
SET @i = 0
WHILE(@i < @n)
BEGIN
...
@i = @i + 1
END
Par ailleurs, pour parcourir toutes les lignes d’une table, il suffit bien souvent d’utiliser l’instruction
SELECT. Les boucles sont donc inutiles en général.
Modes d'exécution du code SQL
Une fois qu’on a écrit (sans erreur) son code, SQL étant un langage interprété, on peut décider quand
et comment l’exécuter. La première étape consiste bien souvent à préciser sur quelle base de données on
compte travailler. Pour cela on dispose de l’instruction USE. Exemple :
et comment l’exécuter. La première étape consiste bien souvent à préciser sur quelle base de données on
compte travailler. Pour cela on dispose de l’instruction USE. Exemple :
USE northwind
Exécution immédiate
Dans l’Analyseur de requête, s´electionner la partie du code à exécuter et taper sur F5, CTRL+E,ALT+X ou cliquer sur le bouton lecture.
Utilisation de script
On peut enregistrer le code SQL dans des fichiers textes d’extension .sql (il s’agit-là d’une convention que l’on adopte) pour les exécuter plus tard. Sous MS-DOS, on peut exécuter un script truc.sql avec l’utilitaire osql en tapant :
osql -i truc.sql
Exécution par lots
Dans l’utilitaire osql on peut également taper les lignes une par une et taper GO pour lancer l’exécution. Les instructions entre deux GO successifs forment un lot. Si une erreur existe dans un lot, aucune instruction ne sera réellement exécutée. Le lot passe donc soit en totalité, soit pas du tout.
On peut écrire les GO dans un script, mais on pr´ef´erera utiliser les transactions.
On peut écrire les GO dans un script, mais on pr´ef´erera utiliser les transactions.
Transactions
Une transaction est une suite d’instructions qui réussissent ou qui échouent en totalité (pas de réussite partielle). Si elle réussit, les modifications apportées à la base sont permanentes, et la transaction est inscrite au journal. Si une instruction échoue, toute la transaction est annulée et la base retrouve l’état dans lequel elle était avant la transaction.
Toutes les transactions figurent dans un fichier que l’on appelle le journal des transactions. Ce journal permet de restaurer la base de données en cas de panne sur le ou les fichiers de données. Ces fichiers de donnéessont évidemment sauvegard´es régulièrement, mais pour pouvoir restaurer compl`etement la base (en cas de plantage) il faut pouvoir refaire toutes les modifications depuis la dernière sauvegarde. C’est le role du journal des transactions de contenir toutes ces informations. Il est donc généralement stocké sur un autre disque.
Toutes les transactions figurent dans un fichier que l’on appelle le journal des transactions. Ce journal permet de restaurer la base de données en cas de panne sur le ou les fichiers de données. Ces fichiers de donnéessont évidemment sauvegard´es régulièrement, mais pour pouvoir restaurer compl`etement la base (en cas de plantage) il faut pouvoir refaire toutes les modifications depuis la dernière sauvegarde. C’est le role du journal des transactions de contenir toutes ces informations. Il est donc généralement stocké sur un autre disque.
On dit qu’une transaction est ACID :
- Atomique, au sens ou on ne peut pas la diviser en une partie qui échoue et une partie qui réussit ;
- Consistante, au sens ou une fois la transaction terminée, la base est de nouveau dans un état cohérent ;
- Isolée, au sens ou une transaction considère que, pendant son ex´ecution, les données qu’elle manipule ne sont pas modifiées par une autre transaction ;
- et Durable, au sens ou les modifications opérées par la transaction sont enregistrées de façon permanente (et recouvrables en cas de reconstruction de la base).
La syntaxe pour d´elimiter une transaction est la suivante :
BEGIN TRAN
... une suite d’instructions
COMMIT TRAN
BEGIN TRAN
... une suite d’instructions
COMMIT TRAN
C’est une notion importante : si le transfert d’une somme d’argent est encapsulé dans une transaction
qui regroupe le débit du compte source et le crédit du compte destination, alors il n’y aura pas de fuite
d’argent même en cas d’erreur.
qui regroupe le débit du compte source et le crédit du compte destination, alors il n’y aura pas de fuite
d’argent même en cas d’erreur.
Débogage
Il n’y a pas dans SQL Server de débogage à proprement parler. Tout juste dispose-t-on d’une vérification de la syntaxe des requêtes SQL. Il faut donc se débrouiller avec l’affichage des résultats
à l’écran.
à l’écran.





Aucun commentaire :
Enregistrer un commentaire